Diffusion Models for Image Generation#
As previously introduced, in this final chapter we will discuss more in details the working mechanism of Diffusion Models, the state-of-the-art for image generation.
Introduction to Diffusion Models#
Diffusion models are a class of generative models that produce data samples by iteratively denoising a Gaussian noise vector. Unlike GANs or VAEs, they are likelihood-based models that combine principles from non-equilibrium thermodynamics and probabilistic modeling.
The key idea is to define a Markov chain that slowly destroys the structure of data by adding Gaussian noise over several steps, and then train a neural network to reverse this noising process, recovering the original data.

The Forward Process: Gradual Noising#
Let \(x_0 \sim p_{\text{data}}(x)\) be a sample from the real data distribution.
We define a sequence of latent variables \(x_1, x_2, \ldots, x_T\) where noise is added at each step according to a predefined variance schedule \( \beta_1, \dots, \beta_T\). The forward (noising) process is defined as:
This is a Markov process that gradually transforms the data into pure noise.
We can also write the marginal distribution of \(x_t\) directly given \(x_0\) as:
where:
Intuitively, as \(t \to T\), \(x_t\) becomes close to an isotropic Gaussian \(\mathcal{N}(0, I)\).
The Reverse Process: Learning to Denoise#
Our goal is to learn the reverse-time process:
Unlike the forward process, this is not known analytically. We approximate it using a neural network parameterized by \(\theta\).
Assuming a Gaussian form for the reverse conditional:
Most models fix \(\Sigma_\theta\) and train the network to predict only the mean (or alternatively the noise that was added, as we’ll see next).
Denoising Score Matching (Simplified View)#
Rather than modeling the full posterior \(p_\theta(x_{t-1} \mid x_t)\), the training objective is simplified by using denoising score matching. The network learns to predict the noise \(\epsilon\) added at each step:
A neural network \(\epsilon_\theta(x_t, t)\) is trained to minimize the expected squared error:
This formulation greatly simplifies training and leads to excellent sample quality.
Summary of Diffusion Model Structure#
Forward process: adds small amounts of Gaussian noise step-by-step to data
Reverse process: learned by a neural network to denoise
Final sample generation: starts from pure Gaussian noise and applies the learned denoising steps
This framework allows for stable training, unlike GANs, and for high-quality image synthesis, often outperforming VAEs and GANs in perceptual quality.
Training Diffusion Models#
Once we have defined the forward noising process and the reverse denoising model, the training phase consists in teaching the neural network to predict the noise that was added to a clean image.
We use a time-dependent neural network \(\epsilon_\theta(x_t, t)\) that receives as input a noisy image \(x_t\) and a timestep \(t\), and tries to estimate the noise \(\epsilon\) used to corrupt the original clean image \(x_0\).
Recap: Sampling from the Forward Process#
Recall that we can sample a noisy image \(x_t\) directly given the clean image \(x_0\) as:
This gives us a way to synthetically generate training data pairs ((x_t, \epsilon)) from a dataset of real images \(x_0\).
The Loss Function#
The model is trained by minimizing the mean squared error between the predicted noise and the actual sampled noise:
This approach has the following advantages:
It avoids explicitly computing the reverse conditional distribution.
It is simple to implement.
It works well in practice.
Training Procedure in PyTorch#
Here is a minimal example of how this training step might look like using PyTorch:
import torch
import torch.nn as nn
def get_alphas(beta_schedule):
beta = torch.tensor(beta_schedule)
alpha = 1.0 - beta
alpha_bar = torch.cumprod(alpha, dim=0)
return alpha, alpha_bar
class SimpleUNet(nn.Module):
def __init__(self):
super().__init__()
# Minimal UNet-like model for illustration
self.net = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 3, 3, padding=1),
)
def forward(self, x, t):
# Embed time as additional channel or via positional encoding
return self.net(x)
# Assume we already have: x0: (B, C, H, W), sampled from data
# t: timestep indices uniformly sampled in [1, T]
def sample_xt(x0, t, alpha_bar):
sqrt_alpha_bar = torch.sqrt(alpha_bar[t])[:, None, None, None]
sqrt_one_minus_alpha_bar = torch.sqrt(1 - alpha_bar[t])[:, None, None, None]
noise = torch.randn_like(x0)
xt = sqrt_alpha_bar * x0 + sqrt_one_minus_alpha_bar * noise
return xt, noise
# Training step
def training_step(model, x0, t, alpha_bar, optimizer):
xt, noise = sample_xt(x0, t, alpha_bar)
pred_noise = model(xt, t)
loss = nn.MSELoss()(pred_noise, noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
Image Generation#
Once the model has been trained to predict the noise added during the forward process, we can generate new images by reversing the diffusion process. This process begins from pure Gaussian noise and proceeds step-by-step, applying the learned denoising network.
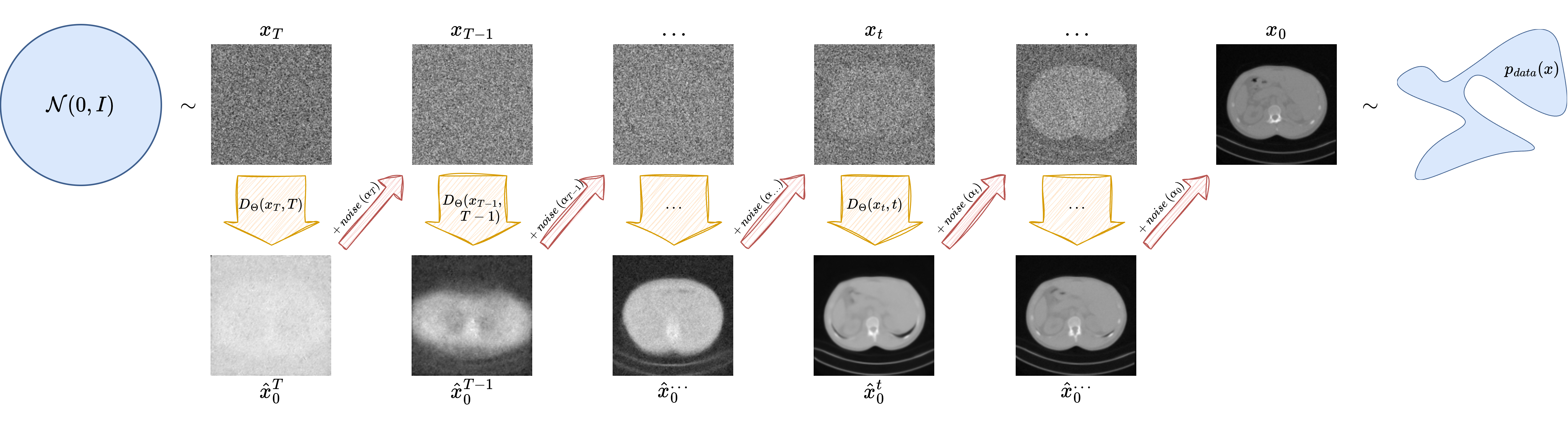
The Reverse Sampling Process#
Given a trained model \(\epsilon_\theta(x_t, t)\), we start from \(x_T \sim \mathcal{N}(0, I)\) and apply the following iterative update:
where:
\(\alpha_t = 1 - \beta_t\)
\(\bar{\alpha}_t = \prod_{s=1}^t \alpha_s\)
\(z \sim \mathcal{N}(0, I)\) is fresh Gaussian noise
\(\sigma_t^2\) is typically set to \(\beta_t\), the variance of the forward process
At each step, we use the network to predict the noise added to \(x_t\), and subtract it out to get \(x_{t-1}\), optionally adding some randomness (except at \(t = 1\)).
Pseudocode of the Sampling Process#
Here is a simplified description of the denoising loop:
@torch.no_grad()
def sample(model, image_size, T, alpha, alpha_bar, beta):
device = "cpu" # Set device
x = torch.randn(1, 3, image_size, image_size).to(device) # Start from pure noise
for t in reversed(range(1, T)):
t_tensor = torch.full((1,), t, dtype=torch.long).to(device)
epsilon_theta = model(x, t_tensor)
alpha_t = alpha[t]
alpha_bar_t = alpha_bar[t]
beta_t = beta[t]
coef1 = 1 / torch.sqrt(alpha_t)
coef2 = (1 - alpha_t) / torch.sqrt(1 - alpha_bar_t)
mean = coef1 * (x - coef2 * epsilon_theta)
if t > 1:
noise = torch.randn_like(x)
sigma = torch.sqrt(beta_t)
x = mean + sigma * noise
else:
x = mean # Final step: no noise added
return x